Since the emergence of cloud services such as AWS, Azure, Google Cloud, more and more co-operations are moving away from on-premises infrastructure, saving them investment & maintenance costs and alleviating from infrastructure management. As the size and complexity of the application grows, manual setup becomes time consuming and prone to errors. Large applications require multiple cloud resources, custom configuration and role/user based permissions. In order to automate the provisioning of the resources and efficiently manage the manual processes, the concept of infrastructure as code, similar to programming scripts, has become more prevalent.
Infrastructure as Code (IoC)
Infrastructure as code codifies and manages underlying IT infrastructure as software. It allows to easily setup multiple environments to develop, test and pilot the application. All the environment are consistent with the production environment given the same code is used to setup all the environments. With the infrastructure setup written as code, it can go through the same version control, automated testing and other steps of a continuous integration and continuous delivery (CI/CD) pipeline similar to application code. Infrastructure as code does requires additional tools, such as a configuration management and automation/orchestration system which could introduce learning curves and room for errors.
Immutable infrastructure is preferred for high scalable cloud and microservices environments, were a set of components and resources are assembled to create a full service or application. When a change is required for any component, they are not changed or reconfigured, but they are all updated and effectively redeployed in an instance. Mutable infrastructure on the other hand is preferred in legacy systems, were the infrastructure components are changed in production, while the overall service or application continues to operate as normal.
Infrastructure-as-code can be declarative and imperative. A declarative programming approach outlines the desired, intended state of the infrastructure, but does not explicitly list the steps to reach that state, e.g.
AWS CloudFormation templates. An imperative approach defines commands that enable the infrastructure to reach the desired state, for example
Chef script and
Ansible. In both the approaches we have a template which specifies the resources to be configured on each server and allows to verify or setup the corresponding infrastructure.
Infrastructure-as-code tools configure and automate the provisioning of infrastructure. These tools can automatically execute the deployment of infrastructure, such as servers, along with orchestration functionality. They also can configure and monitor previously provisioned systems. These tools enforce the setup from the template via push or pull methods. They also enable to roll back changes to the code, as in the event of unexpected problems from an update.
Terraform
Terraform is an open-source infrastructure as Code tool developed by
HashiCorp. It is used to define and provision the complete infrastructure using its declarative
HashiCorp Configuration Language (HCL). It also supports JSON configuration. It enables to store the cloud infrastructure setup as code. Terraform manages the life cycle of the resources from its provisioning, configuration and decommissioning. Compared to CloudFormation which only allows to automate the AWS infrastructure, Terraform works with multiple cloud platform such as
AWS,
Azure,
GCP,
DigitalOcean and many more. It supports multiple tiers such as
SaaS,
PaaS and
IaaS. Terraform provides both configuration management and orchestration. Terraform can be used for creating or provision new infrastructure, managing existing infrastructure, and to replicate infrastructure. Terraform allows to define infrastructure in a config file, which can be used to track infrastructure changes using source control, and can be used to build and deploy the infrastructure.
To install Terraform, download the
latest available binary package, unzip the archive into a directory and include the path to binary (bin) directory in system PATH environment variable. Set the Terraform plugin cache by creating a ~/.terraformrc file and adding:
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"
Terraform Architecture
Terraform has three main components, the Core, the Plugins and Upstream APIs.
The Core is responsible for reading configuration and building the dependency graph. It creates a plan of what resources needs to be created/changed/removed.
Terraform Plugins are external single static binaries with the Terraform Provider Plugin as the most common type of plugin. During the planning and applying phases, Terraform's Core communicates with the plugins via an RPC interface. Terraform Provider Plugins implement resources with a basic CRUD (create, read, update, and delete) API for communicating with third party services. The providers makes it possible to create infrastructure across all this platforms.
Upstream APIs are third party, external services with which Terraform interacts. The Terraform Core asks the Terraform Provider Plugin to perform an operation, and the plugin communicates with the upstream API.
HashiCorp Configuration Language (HCL)
HCL syntax is defined using blocks which contains arguments and configuration data represented as key/value pairs . Block syntax usually has the block name e.g. resource, followed by the Resource type which is dependent on the provider e.g. "local_file" and finally the resource name in order to identify the resource. The resource type contains the provider type (e.g. local, AWS etc) before the underscore, followed by the actual resource type (e.g. file, EC2 etc). The arguments of the resource depends on the type of the provider and type of the resource being created. Each resource type expects specific arguments to be provided.
Syntax:
key1 = value1}
resource "local_file" "config" {
filename = "/root/config.txt"
content = "This is system config."
}
Terraform Core Commands
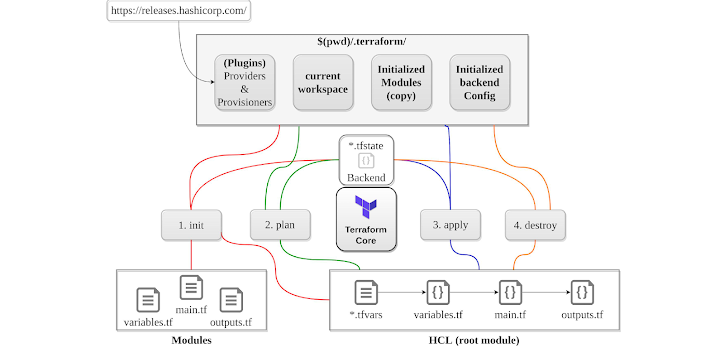
Init Command
Init command is the first command to run before we can start using Terraform. The terraform binary contains the basic functionality for Terraform and does not come with the code for any of the providers (e.g., AWS provider, Azure provider, GCP provider, etc). The init command checks the terraform configuration file and initializes the working directory containing the .tf file. Terraform executes the code in the files with the .tf extension. Based on the provider type declared in the configuration, it downloads the plugins to work with the corresponding resources declared in the tf file. By default, the provider code will be downloaded into a .terraform folder. It also downloads the additional modules referenced by the terraform code. The init command also sets up the backend for storing the Terraform state file, which allows Terraform to track resources. The init command can be ran multiple times as it is idempotent.
In order to initialize Terraform working directory without accessing any configured remote backend, we use below command.
$ terraform init -backend=false
The -upgrade flag upgrades all modules and providers to the latest version.
$ terraform init -upgrade
Plan Command
Plan command reads the terraform code and shows the actions that would be carried out by terraform to create the resources. The output of the
plan command shows the differences, were resources with a plus sign (+) are going to be created, resources with a minus sign (-) are going to be deleted, and resources with a tilde sign (~) are going to be modified in-place. It allows users to review the action plan before execution and ensure that all the actions performed by the execution/deployment plan are as desired. The plan command does not deploy anything and is considered as a read-only command. Terraform uses the authentication credentials to connect to cloud platform were the infrastructure is to be deployed.
The -out=FILE option allows to save the generated plan into a file.
$ terraform plan -out <file-name>
The -destroy option outputs the destroy plan.
$ terraform plan -destroy
To plan only a specific target module
$ terraform plan -target module.<module-name>
Apply Command
Apply command It executes the actions proposed in a Terraform plan and makes the infrastructure changes into the cloud platform. Terraform executes the code in the files with the .tf extension. It displays execution plan once again, ask confirmation to create the resources. Once confirmed it creates the specified resources. It also updates the deployment changes into the state file which keeps track of all infrastructure updates. The state file can be stored locally or in remote location and usually named as "terraform.tfstate" by default.
$ terraform apply
The --auto-approve flag skips the interactive approval prompt to enter "yes" before applying the plan.
$ terraform apply --auto-approve
The apply command can also the filename of a saved plan file created earlier using terraform plan command -out=... and directly apply the changes without any confirmation prompt.
$ terraform apply <saved-plan-file>
The below command apply/deploy changes only to the targeted resource. The
resource address syntax is used to specify the target resource.
$ terraform apply -target=<resource-address>
$ terraform apply -target=aws_instance.my_ec2
The -lock option (enabled by default) holds the lock to the state file so that others cannot concurrently run commands against the same workspace and modify the state file.
$ terraform apply -lock=true
The terraform apply command can pass the -lock-timeout=<time> argument which tells Terraform to wait up to the specified time for the lock to be released. Another user cannot execute apply command with the same terraform state file until the lock is released. In the below example the lock will be released after 10 minutes.
$ terraform apply -lock-timeout=10m
The -refresh=false option is used to not reconcile state file with real-world resources.
$ terraform apply refresh=false
The parallelism option limits the number of concurrent (resource) operations as Terraform walks the graph. By default its value is 10.
$ terraform apply --parallelism=5
The -refresh-only option only updates Terraform state file and any module output values to match with all the managed remote objects outside of Terraform. It reconciles the Terraform state file with real-world resources. It replaces the old deprecated
terraform refresh command.
$ terraform apply -refresh-only
The -var option is used in both terraform plan and terraform apply commands to pass input variables.
$ terraform apply -var="<variable-name>=<value>"
$ terraform apply -var="image_id=ami-abc123" -var="instance_type=t2.micro"
In order to set lots of variables, the variables & their values are specified in a variable definitions file .tfvars or .tfvars.json, and passed with -var-file option to the apply command.
$ terraform apply -var-file=<your file>
Destroy Command
Destroy command It looks at the recorded, stored state file create during the deployment and destroys all the resources which are being tracked by Terraform state file. This command is a non-reversible command and hence should be used with caution. It good to take backups and ensure that we want to delete all the infrastructure. It is mainly used for cleaning up the resources which are created and tracked using Terraform.
Terraform Providers
Terraform abstracts the integration with API control layer of infrastructure vendors using the Provider. Every cloud vendor has its own provider. Terraform by default looks for providers in the Terraform
providers registry.
Terraform configurations must declare which providers they require so that Terraform can install and use them. Additionally, some providers require configuration (like endpoint URLs or cloud regions) before they can be used. Each provider adds a set of resource types and/or data sources that Terraform can manage. Every resource type is implemented by a provider, which enable Terraform to manage the corresponding cloud infrastructure.
The below command shows information about the
provider requirements for the configuration in the current working directory.
$ terraform providers
Providers can also be sourced locally or internally and referenced with the Terraform code. Providers are plugins which are distributed separately from Terraform itself, and each provider has its own series of version numbers. It is recommended to use specific version of terraform providers in the terraform code. We can also write a customer provider s. Terraform finds and installs the providers when initializing the working directory using the terraform init command. The terraform providers are downloaded in a hidden directory named .terraform.
Configuring the Provider
provider "aws" {
version = "3.7.0"
region = "us-west-1"
assume_role {
role_arn = local.provider_role
session_name = "Terraform"
}
}
provider "google" {
version = "2.20.0"
credentials = file("credentials.json")
project = "my-gcp-project"
region = "us-west-1"
}
Resource
A resource is an object managed by Terraform. Terraform manages the life cycle of the resources from its provisioning, configuration and decommissioning. The resource block creates a new resource from scratch. The resource block has a number of required or optional arguments that are needed to create the resource. Any missing optional configuration in the configuration parameters uses default value.
Syntax:
resource "<provider>_<type>" "<name>" {
<config> ...
}
<provider> is the name of a provider (e.g., aws)
<type> is the type of resources to create in that provider (e.g., instance, security_group)
<name> is an identifier or name for the resource
<config> consists of one or more arguments that are specific to that resource (e.g., ami = "ami-0c550")
We can also specify
inline blocks as an argument to attribute set within a resource.
Syntax:
resource "<provider>_<type>" "<name>" {
where <name> is the name of the inline block (e.g. tag) and <config> consists of one or more arguments that are specific to that inline block (e.g., key and value).
resource "aws_instance" "web" {
ami = "ami-a1b2c3d4",
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.instance.id]
tag {
key = "Name"
value = var.cluster_name
propagate_at_launch = true
}
}
Each provider has a unique set of resources that can be created on the specified platform. Below is an example of creating a docker container using terraform resource.
#Image used by the container
resource "docker_image" "terraform-centos" {
name = "centos:7"
keep_locally = true
}
# Create a container
resource "docker_container" "centos" {
image = docker_image.terraform-centos.latest
name = "terraform-centos"
start = true
command = ["/bin/sleep", "500"]
}
The syntax for resource reference is <provider>_<type>.<resource-name>, for example. aws_instance.web. To access the resource attribute i.e. the arguments of the resource (e.g., name) or one of the attributes exported by the resource we use the use, <provider>_<type>.<resource-name>.<attribute>, e.g. aws_instance.web.instance_type.
It is important to note that, to change the identifiers in Terraform requires a state change. The parameters of many resources are immutable, hence Terraform will delete the old resource and create a new one to replace it. Most of the cloud provider's API such as AWS, are asynchronous and eventually consistent. Eventually consistent means it takes time for a change to propagate throughout the entire system, so for some period of time, we may get inconsistent responses. Usually wait and retry after some time approach is used until the action is completed and the changes propagated.
Local-only Resources operate only within Terraform itself. The behavior of local-only resources is the same as all other resources, but their result data exists only within the Terraform state. Local-only resource types exist for generating private keys, issuing self-signed TLS certificates, and even generating random ids.
When we add a reference from one resource to another, we create an
implicit dependency. Terraform parses these dependencies, builds a dependency graph from them, and uses it to automatically figure out the order in which to create resources. For example, when creating an EC2 instance above, Terraform would know it needs to create the security group before the EC2 Instance, since the EC2 Instance references the ID of the security group. Terraform walks through the dependency tree, creating as many resources in parallel as it can.
Meta-Arguments
Count Meta-Argument
Every Terraform resource has a meta-Argument called count which helps to iterate over the resource to create multiple copies. In the below example the count parameter creates three copies of the IAM users. The count.index allows to get the index of each iteration in the count loop.
resource "aws_iam_user" "example" {
count = 3
name = "neo.${count.index}"
}
Another example of creating resources with different names from an array variable.
resource "aws_iam_user" "example" {
count = length(var.user_names)
name = var.user_names[count.index]
}
When count argument is set to value in a resource block, it becomes a list of resources, rather than just one resource. If the count parameter is set to 1 on a resource, we get single copy of that resource; if the count is set to 0, the resource is not created. In order to read an attribute from the resource list, we need to specify the index in the resource list. The syntax to read a particular resource in resource list is as below.
<provider>_<type>.<name>[index].<attribute>
Although count argument allows to loop over an entire resource, it cannot be used to loop over inline blocks. Also since terraform identifies each resource within the array by its index position, if an item is removed from array, it causes all other items after to shift back by one, hence incorrectly causing terraform to rename resources rather than deleting them. Count is used when the instances are almost identical and can directly derived from an integer.
For-Each Meta-Argument
The for_each expression allows to loop over lists, sets, and maps to create multiple copies of either an entire resource or an inline block within a resource. It can be used with modules and with every resource type. The syntax of for_each is as below:
resource "<provider>_<type>" "<name>" {
for_each = <collection>
[config ...]
}
where <provider> is the name of a provider (e.g. aws), <type> is the type of resource to create in the provider (e.g. instance), <name> is an identifier of the resource, <collection> can be a set or map to loop over (lists are not supported when using for_each on a resource) and <config> is one or more arguments that are specific to that resource. In the for_each block, an additional each object is available which allows to modify the configuration of each instance. We can use each.key and each.value to access the key and value of the current item in <collection>, within the <config> parameters.
In the below example, for_each loops over the set (converted from list) and makes each value of user_names set available in each.value. When looping a map, each.key is used to get each key, while each.value gets each value. Terraform transforms the resource with for_each into a map of resources.
resource "aws_iam_user" "example_accounts" {
for_each = toset( ["Todd", "James", "Alice", "Dottie"] )
name = each.value
}
resource "azurerm_resource_group" "rg" {
for_each = {
a_group = "eastus"
another_group = "westus2"
}
name = each.key
location = each.value
}
for_each is preferred over count most of the time, as reflects changes (add/delete) in the collection, into terraform resource plan. for_each also allows to create multiple inline blocks within a resource. Below is the syntax of for_each to dynamically generate inline blocks.
dynamic "<variable_name>" {
for_each = <collection>
content {
[<config>...]
}
}
where <variable_name> is variable name which stores the value each iteration, <collection> is a list or map to iterate over, and the content block is what to generate from each iteration. We can us <variable_name>.key and <variable_name>.value within the content block to access the key and value, respectively, for the current item in the <collection>.
When using for_each with a list, the key will be the index and the value will be the item in the list at that index, and when using for_each with a map, the key and value will be one of the key-value pairs in the map.
variable "custom_tags" {
description = "Custom tags to set on the Instances in the ASG"
type = map(string)
default = {}
}
resource "aws_autoscaling_group" "example_asg" {
dynamic "tag" {
for_each = var.custom_tags
content {
key = tag.key
value = tag.value
propagate_at_launch = true
}
}
}
When an empty collection is passed to a for_each expression, it produces no resources or inline blocks. For a non-empty collection, it creates one or more resources or inline blocks. Terraform requires that it can compute count and for_each during the plan phase, before any resources are created or modified. Hence count and for_each cannot contain reference to any resource outputs. Terraform also currently does not support count and for_each within a module configuration.
Depends-On Meta-Argument
Most of the resources in terraform configuration don't have any relationship with each other, hence Terraform can make changes to such unrelated resources in parallel. But some resources are dependent on other resources and requires information generated by another resource. Terraform handles most of the resource dependencies automatically. Terraform analyses any expressions within a resource block to find references to other objects, and treats those references as implicit ordering requirements when creating, updating, or destroying resources. However in some cases, dependencies cannot be recognized implicitly in configuration, e.g. resource creation can have a hidden dependency on access policy. In such rare cases the depends_on meta-argument can explicitly specify a dependency.
The depends-on meta-argument is used to handle the hidden resource or module dependencies which cannot be inferred by Terraform automatically. It specifies that the current resource or module relies on the other dependent resources for its behavior, without accessing the dependent resource's data in its arguments. The depends-on meta-arguments is available in module blocks and in all the resource blocks. The depends-on meta-argument is a list of references to other resources or child modules in the same calling module. The depends-on meta-argument is used as a last resort to explicitly specify a dependency.
resource "aws_rds_cluster" "this" {
depends_on = [
aws_db_subnet_group.this,
aws_security_group.this
]
}
Lifecycle Meta-Argument
The lifecycle meta-argument is a nested block within a resource block and enables to customize the lifecycle of the resource. Below are the arguments used within a lifecycle block.
create_before_destroy (bool): By default, When Terraform needs to update a resource in-place, it first destroys the existing object and then creates a new replacement object. The create_before_destroy meta-argument changes this behavior by first creating the new replacement object, and then once replacement created, destroys the previous object. It does require that the remote object accommodate unique name and other constraints (by appending random suffix), so that both the new and old objects can exist concurrently.
prevent_destroy (bool): When enabled, this meta-argument causes Terraform to reject with an error any plan that would destroy the infrastructure object associated with the resource, as long as the argument and resource block remains present in the configuration. It provides safety against accidental replacement of objects which can be costly to reproduce.
ignore_changes (list of attribute names): Terraform by default detects any changes in current real world infrastructure objects and plans to update the remote object to match configuration. The ignore_changes allows to ignore certain changes to the resource after its creation. It specifies resource attributes as Map or list (or special keyword all), which Terraform would ignore when planning updates to the associated remote object.
resource "azurerm_resource_group" "example" {
lifecycle {
create_before_destroy = true,
ignore_changes = [
# Ignore changes to tags
tags
]
}
}
Input Variable
Terraform input variables act as input parameters passed at runtime to customize the terraform deployments. Below is the syntax for declaring an input variable.
Syntax:
variable "my-var" {
description = "Example Variable"
type = string
default = "Hello World"
}
The body of the variable declaration can contain three parameters, description, default, type, which are all optional. The value of the variable can be provided by using the -var option from command line or the -var-file option via a file, or via an environment variable using the name TF_VAR_<variable_name>. If no value is passed in, the variable will fall back to this default value. If there is no default value, Terraform will interactively prompt the user for one. Terraform supports a number of type constraints, including string, number, bool, list, map, set, object, tuple, and any (which is default value).
Since all the variable configuration parameters are optional, a variable can also be defined as below. The value for the below variable needs be passed using environment variable or using command line arguments to avoid runtime error.
variable "my-var" {}
A variable reference is used to get the value from an input variable in Terraform code. Variables can be referenced using the notation var.<variable-name>. Variables are usually defined in terraform.tfvars file, which by default loads all the variables.
Terraform provides variable validation, which allows to set a criteria for allowed values for a variable. Terraform checks if the value of the variable meets the validation criteria before deploying any infrastructure changes.
variable "my-var" {
description = "Example Variable"
type = string
default = "Hello World"
validation {
condition = length(var.my-var) > 4
error_message = "The string must be more than 4 characters"
}
}
The sensitive configuration parameter prevents the value of the variable being displayed during terraform execution.
variable "my-var" {
description = "Example Variable"
type = string
default = "Hello World"
sensitive = true
}
Variable Types Constraints
Base Types:
Complex Types:
- list, set, map, object, tuple
1) Example of list type variable.
variable "availability_zones" {
type = list(string)
default = ["us-west-1a"]
}
2) Example of list of object type variable.
variable "docker_ports" {
type = list(object({
internal = number
external = number
protocol = string
}))
default = [
{
internal = 8300
external = 8300
protocol = "tcp"
}
]
}
Terraform reads the variables passed through operating system environment variables with higher precedence, followed by the variables defined in the terraform.tfvars file.
Output Variable
Output variables allows to define values in terraform configuration which can be shared with other resources or modules. Terraform defines output variables with the following syntax:
Syntax:
<name> is the name of the output variable,
<value> can be any Terraform expression and
<config> can contain two additional parameters, both optional: description and sensitive (true not to log this output at the end, .e.g. passwords).
The value is a mandatory config argument which can be assigned any value or reference values of other terraform resources or variables. Output also provides the sensitive configuration argument to hide the sensitive variable values.
output "instance_ip" {
description = "Private IP of VM"
value = aws_instance.my-vm.private_ip
}
The terraform apply command not only applies the changes, but also shows the output values on the console. We can also use the terraform output command to list all outputs without applying any changes. The -json option formats the output as a JSON object.
$ terraform output
$ terraform output -json
To check the value of a specific output called <output-variable>, we can run the below command.
$ terraform output <output-variable>
Terraform supports several lifecycle settings which allows to customize how resources are created and destroyed.
create_before_destroy - It controls the order in which resources are recreated. The default order is to delete the old resource and then create the new one. Setting to true reverses this order, creating the replacement first, and then deleting the old one.
prevent_destroy - Terraform rejects with an error any plan that would destroy the infrastructure object associated with the resource, as long as the argument remains present in the configuration.
ignore_changes - By default, Terraform detects any differences in the current settings of a real infrastructure object and plans to update the remote object to match the configuration. It ignores when planning updates to the associated remote object.
A data source represents a piece of read-only information that is fetched from the provider i.e. AWS every time we run Terraform. It's just a way to query the provider's APIs for data and to make that data available to the rest of the Terraform code. Each Terraform provider exposes a variety of data sources. For example, the AWS provider includes data sources to look up VPC data, subnet data, AMI IDs, IP address ranges, the current user’s identity, and much more.
Data Sources
Data sources allow to fetch and track details of already existing resources in Terraform configuration.
While a resource causes Terraform to create and manage a new infrastructure component, data sources on the other hand provides read-only views into pre-existing data and compute new values on the fly within Terraform itself. Providers are responsible in Terraform for defining and implementing data sources. The syntax for using a data source is very similar to the syntax of a resource:
Syntax:
data "<provider>_<type>" "<name>" {
<provider> is the name of a provider (e.g., aws),
<type> is the type of data source (e.g., vpc),
<name> is an identifier to refer to the data source, and
<config> consists of one or more arguments that are specific to this data source.
data "aws_instance" "my-vm" {
instance_id = "i-4352435234dsfs0"
}
In order to access the above data source, we use the syntax data.<provider>_<type>.<name>, example data.aws_intance.my-vm. The attribute of the data source can in turn accessed as data.<provider>_<type>.<name>.<attribute>.
Local Values
A
local value assigns a name to an expression, so you can use it multiple times within a module without repeating it. A set of related local values can be declared together in a single locals block. Local values can be literal constants or can reference to other values such as variables, resource attributes, or other local values in the module. Local values can refer the local values in same block as long as they don't introduce any circular dependencies. The local values can be referenced using
local.<name>. Local values help to avoid repeating the same values or expressions multiple times in terraform configuration.
locals {
instance_ids = concat(aws_instance.blue.*.id, aws_instance.green.*.id)
}
locals {
common_tags = {
Service = local.service_name
Owner = local.owner
}
}
resource "aws_instance" "my_instance" {
...
tags = local.common_tags
}
Modules
Module is a collection of terraform code files within a directory, whose output can be referenced in other parts of the project. It is a container for multiple resources that are used together. Modules is used to group together multiple resources which are used together in a project. Modularization allows to make the code reusable.
The main working directory which holds the terraform code is called the root module. The modules which are referenced from root modules are called the child modules, which can be passed input parameters and can fetch outputs values. Modules can be download or referenced from either Terraform Public Registry, a Private Registry or Local file system. The syntax for module is as below:
module "<name>" {
source = "<source>"
<config> ...
}
Modules are referenced using the module block which is shown in the below example.
module "my-vpc-module" {
source = "./modules/vpc" # Module source (mandatory)
version = "0.0.5" # Module version
region = var.region # Inputs parameter for the module
}
Other parameters allowed inside the module block are as below
- count allows spawning multiple separate instances of module's resources.
- for_each allows iterating over complex vairables,
- providers allows to tie down specific providers for the module,
- depends_on allows to set dependencies for the module.
Note that whenever we add a module to the Terraform configurations or modify the source parameter of a module, we need to run the init command before we run the plan or apply command. The init command downloads providers, modules, and configures the backends.
Modules can optionally take arbitrary number of inputs and return outputs to plug back into the main code. Terraform Module inputs are arbitrarily named parameters that can be passed inside the module block. These inputs can be used as variables inside the module code. Below is the example were `server-name` input parameter is passed to the module, and can be referenced as 'var.server-name' inside the module.
module "my-vpc-module" {
source = "git::ssh://git@github.com/emprovise/terraform-aws-vpc?ref=v1.0.5"
name = "monitoring-vpc"
server-name = 'us-east-1' # Input parameter for module
}
The outputs declared inside the module code can be fed back into the root module or the main code. The syntax to read the output inside the module code from outside terraform code is module.<module-name>.<output-name>.
The value of the below output block can be access using module.my-vpc-module.subnet_id from outside the module.
output "subnet_id" {
value = aws_instance.subnet_id
}
resource "aws_instance" "my-vpc-module" {
.... # other arguments
subnet_id = module.my-vpc-module.subnet_id
}
Terraform configuration files naming conventions:
- variables.tf: Input variables.
- outputs.tf: Output variables.
- main.tf: The actual resources.
Terraform Configuration Block
Terraform configuration block is a specific configuration block for controlling Terraform's own behavior. The terraform block only allows constant values, with no reference to named objects such as resources, input variables, etc, or any usage of the Terraform built-in functions. It allows to configure various aspects of terraform workflow such as:
- Configuring backend with nested backend block for storing state files.
- Specifying a required Terraform version (required_version), against which the Terraform code is executed.
- Specifying a required Terraform Provider version with required_providers block.
- Enabling and testing Terraform experimental features using experiments argument.
- Passing provider metadata (provider_meta) for each provider of the module.
Below is an example of terraform configuration block which ensures that Terraform only runs when the Terraform binary version is above 0.13.0 and Terraform AWS provider version is above 3.0.0, using regular expression.
terraform {
required_version = ">=0.13.0"
required_providers {
aws = ">=3.0.0"
}
}
# Configure Docker provider
terraform {
required_providers {
docker = {
source = "terraform-providers/docker"
}
}
required_version = ">=0.13"
}
Terraform Backend
Terraform Backend defines the state snapshot storage and operations to create, read, update, or destroy resources. Terraform supports multiple built-in backend types each with their own set of configuration arguments. Terraform backend types are divided into two main types, Enhanced backends which can store state and perform operations e.g. local and remote, and the Standard backend which only stores state and rely on local backend for performing operations e.g.
consul,
artifactory etc.
Terraform only allows a single backend block within the configuration and does not allow references to input variables, locals, or data source attribute. If a configuration includes no backend block, Terraform defaults to using the local backend, which performs operations on the local system and stores state as a plain file in the current working directory. After updating the backend configuration, terraform init should be ran to validate and configure the backend before performing any plans, applies, or state operations. Terraform allows to omit certain required arguments which can be passed later by Terraform automation script. It although requires at least an empty backend configuration to be specified in root Terraform configuration file. The omitted required arguments can be passed using configuration file with -backend-config=PATH option, key/value pairs with -backend-config="KEY=VALUE" option, or using interactive prompt while running terraform init command. Terraform allows to change backend configuration along with the backend type or remove the backend altogether. In order for the configuration changes to take affect, terraform requires to be reinitialized using terraform init.
Below is an example of the Backend configuration.
terraform {
backend "remote" {
organization = "emprovise"
workspaces {
name = "terraform-prod-app"
}
}
}
In the below example of backend configuration, we create an S3 bucket by using the aws_s3_bucket resource, with "sse_algorithm" as "AES256" to securely store state files. Then a DynamoDB table is created which has a primary key called LockID to enable locking on state files in S3 bucket. The below backend configuration uses the S3 bucket to store terraform state file and DynamoDB table to prevent multiple users acquiring loack to the state file.
terraform {
backend "s3" {
bucket = "terraform-up-and-running-state"
key = "global/s3/terraform.tfstate"
region = "us-east-2"
dynamodb_table = "terraform-up-and-running-locks"
encrypt = true
}
}
Terraform State
Terraform State is a mechanism for Terraform to keep track of the deployed resources, which is used to determine the actions to be taken to update the corresponding platform. Terraform state is the blueprint of the infrastructure deployed by Terraform. Terraform determines the state of the deployed resources to decide whether to create new resources from scratch, modified or even destroyed. Terraform records information about the real world infrastructure it creates into the
Terraform state file. By default, Terraform creates the json state file named
terraform.tfstate in the current directory. The
state file contains a custom JSON format that records a mapping from the Terraform resources in our templates to the representation of those resources in the real world. The state file helps Terraform to calculate the deployment delta and create new deployment plans. Before terraform modifies any infrastructure, it checks and refreshes the state file ensuring that it is upto date with real world infrastructure. Terraform state file also tracks the dependency between the resources deployed, i.e. Resource dependency metadata. Terraform ensures that entire infrastructure is always in defined state at all times. It helps to boost deployment performance by caching resource attributes for subsequent use. Terraform backups the last known state file recorded after successful terraform apply locally. Since state file is critical to Terraform's functionality and losing the state file causes to lose the reference to the cloud infrastructure. Also since all the infrastructure deployed with Terraform ends up in plain text in state file, the state file should always be encrypted, both in transit and on disk. In such case using terraform
import command is only option to get configuration of existing resources in cloud.
Terraform State Command
Terraform State Command is a utility for manipulating (modifying) and reading the Terraform State file. The state command is used for advance state management. It allows to manually remove resources from state file so they are not managed by Terraform, and to list out tracked resources and its details (via state and list commands).
Below state command lists out all the resources that are tracked by the Terraform State file.
$ terraform state list
Below state command shows the details of a resource and its attributes tracked in the Terraform State file.
$ terraform state show <resource-address>
Below command allows to renamed a resource block or move to a different module, but retaining the existing remote object. It updates state to track the resource as a different resource instance address.
$ terraform state mv <source-resource-address> <destination-resource-address>
The below command manually downloads and outputs the state file from remote state or even local state.
$ terraform state pull
The push command manually upload a local state file to remote state. It also works with local state.
$ terraform state push
Below command manually unlocks the locked state file for the defined configuration, using the LOCK_ID provided when locking the state file beforehand.
$ terraform force-unlock LOCK_ID
Below state command deletes a resource from the Terraform State file, there by un-tracking it from Terraform.
$ terraform state rm <resource-address>
Terraform enables to store Terraform State file to a remote data source such as AWS S3, Google Storage and other preset platforms. Remote State Storage allows to share Terraform State file between distributed teams and provides better security, availability and consistent backups in the cloud. Cloud providers can provide granular security policies to access & modify the Terraform State file. Terraform allows state locking so another user cannot execute terraform deployment in parallel which coincides with each other. State locking is common feature across both local and remote state storage. In local state storage, state locking is enabled by default when the terraform apply command is issued. State locking is only supported by few remote state storage platforms such as AWS S3, Google Cloud Storage, Azure Storage and HashiCorp Console. State file also contains the output values from the Terraform code. Terraforms enables to share these output values with other Terraform configuration or code when the State file is stored remotely. This enables distributed teams working remotely on data pipelines requiring successful execution and outputs from the previous Terraform deployment.
Terraform Remote State
Terraform remote state retrieves the state data from a Terraform backend. It allows to use the root-level outputs of one or more Terraform configurations as input data for another configuration. It is referenced by the terraform_remote_state type and because it is a data source, it provides read-only access, so there is no danger of accidentally interfering with the state file. The output variables from the terraform_remote_state is read using the syntax: data.terraform_remote_state.<name>.outputs.<attribute-name>.
data "terraform_remote_state" "vpc" {
backend = "s3"
config {
bucket = "networking-terraform-state-files"
key = "vpc-prod01.terraform.tfstate"
region = "us-east-1"
}
}
resource "aws_instance" "remote_instance" {
subnet_id = data.terraform_remote_state.vpc.outputs.subnet_id
}
Expressions
Terraform supports simple literals as well as complex expressions which help to evaluate values within the Terraform configuration.
Interpolation
The ${ ... } sequence is an interpolation, which evaluates the expression between the markers, converts the result to a string if required, and inserts it into the final string.
"Hello, ${var.name}!"
Directives
Terraform supports directives using the sequence %{ ... }, which allows for conditional evaluation and iteration over collections. The conditional evaluation uses the %{if <BOOL>}/%{else}/%{endif} directive, with the below example.
"Hello, %{ if var.name != "" }${var.name}%{ else }unnamed%{ endif }!"
The iteration over collections is done using %{for <NAME> in <COLLECTION>} / %{endfor} directive. The template is evaluated for each element within the collection and the result for each element is concatenated together.
The template directives can be formatted for readability without adding unwanted spaces or newlines, by adding optional strip markers (~), immediately after the opening characters or immediately before the end of template sequence. The template sequence consumes all of the literal whitespace either at the beginning or end, based on the added strip marker (~).
<<EOT
%{ for ip in aws_instance.example.*.private_ip ~}
server ${ip}
%{ endfor ~}
EOT
Operators
Terraform supports Arithmetic Operators (+, -, *, /, %), Equality Operators (==, !=), Comparison Operators (<, <=, >, >=) and Logical Operators (||, &&, !) in the expressions.
Filesystem Path Variables
Terraform provides special path variables to show filesystem path of terraform modules.
- path.module - Filesystem path of the module where the expression is placed.
- path.root - Filesystem path of the root module of the configuration.
- path.cwd - Filesystem path of the current working directory.
Conditional Expressions
A conditional expression uses the value of a bool expression to select one of two values. The two result values can be of any type, but they both must be of the same type for Terraform to determine the type of whole conditional expression to return.
Syntax: <condition> ? <true-value> : <false-value>
count = var.enable_syn_alarms ? 1 : 0
Splat Expression
A splat expression provides a more concise way to express a common operation that could otherwise be performed with a for expression. The splat expression uses the special [*] symbol which iterates over all of the elements of the list given to its left and accesses from each one the attribute name given on its right.
If var.list is a list of objects, all of which have an attribute id, then a list of the ids could be produced with the following for expression:
[for o in var.list : o.id]
The corresponding splat expression is :
var.list[*].id
A splat expression can also be used to access attributes and indexes from lists of complex types by extending the sequence of operations to the right of the symbol, as shown in below example.
var.list[*].interfaces[0].name
The above expression is equivalent to the following for expression:
[for o in var.list : o.interfaces[0].name]
Terraform provides an array lookup syntax to look up elements in an array at a given index. For example, to look up the element at index 1 within the array var.user_names, we use var.user_names[1].
Expanding Function Arguments
Terraform allows to expand the list or tuple value to pass in as separate arguments to a function. A list value is passed in as an argument and followed by the ... symbol. The general syntax of the function is: function_name(arg1, arg2, ...).
min([55, 2453, 2]...)
For Expression
The for expression allows to iterate over the collection (list, map) and update, filter or create new items within the collection. The basic syntax of a for expression is:
[ for <item> in <list> : <output> ]
[ for <key>, <value> in <map> : <output_key> => <output_value> ]
The <list> is the list being iterated and <item> is local variable assigned each item during iteration. For <map> being iterated, we have <key> and <value> local variables for each entry during the iteration. The <output> is an expression that transforms <item> for list or <key> & <value> for map in some way. Below is an example of for expression converting a list of names to upper case and filtering out the names with less than 5 characters.
variable "names" {
description = "A list of names"
type = list(string)
default = ["neo", "trinity", "morpheus"]
}
output "upper_names" {
value = [for name in var.names : upper(name) if length(name) < 5]
}
We can also use the expressions to output a map rather than list using the below syntax, were curly brackets are used to wrap the expression instead of square brackets and, outputs a key and value separated by an arrow instead of a single value.
variable "hero_thousand_faces" {
description = "map"
type = map(string)
default = {
neo = "hero"
trinity = "love interest"
morpheus = "mentor"
}
}
output "upper_roles" {
value = {for name, role in var.hero_thousand_faces : upper(name) => upper(role)}
}
Built-In Functions
Terraform comes pre-packaged with built-in functions to help transform and combine values. Terraform does not allow user defined functions, but only provides built-in functions, which is extensive list of functions. The built-in functions can be used in terraform code within resources, data sources, provisioners, variables etc.
variable "project-name" {
type = string
default = "prod"
}
resource "aws_vpc" "my-vpc" {
cidr_block = ""
tags = {
Name = join("-", ["terraform", var.project-name]) // terraform-prod
}
}
max(num1, num2, ...): It takes one or more numbers and returns the maximum value from the set.
flatten([["a", "b"], [], ["c"]]): It takes a list and replaces any elements that are lists with a flattened sequence of the list contents e.g. ["a", "b", "c"]. Hence it creates a singular list from a provided set of lists.
contains(list, value): It determines whether the given value is present in the provided list or set.
matchkeys(valueslist, keyslist, searchset): It constructs a new list by taking a subset of elements from one list whose indexes match the corresponding indexes of values in another list.
values({a=3, c=2, d=1}): It takes a map and returns a list containing the values of the elements in that map.
distinct([list]): It takes a list and returns a new list with any duplicate elements removed.
lookup(map, key, default): It retrieves the value for the given key, from the map. If the given key does not exist, the given default value is returned instead.
merge({a="b", c="d"}, {e="f"}): It takes an arbitrary number of maps or objects, and returns a single map or object that contains a merged set of elements from all arguments.
slice(list, startindex, endindex): It extracts elements from startindex inclusive to endindex exclusive from the list.
cidrsubnet(prefix, newbits, netnum): It calculates a subnet address within given IP network address prefix. The prefix is in CIDR notation, newbits is additional no of bits which extend the prefix and netnum is a number represented as a binary integer used to populate the additional bits added to the prefix.
cidrsubnet("10.1.2.0/24", 4, 15)
length(): It determines the length by returning the number of elements/chars in a given list, map, or string.
substr(string, offset, length): It extracts a substring from a given string by offset and length.
keys({a=1, c=2, d=3}): It takes a map and returns a list containing the keys from that map, e.g. ["a", "c", "d"].
toset(["a", "b", "c"]): It converts its argument, a list to a set, remove any duplicate elements and discard the ordering of the elements.
file(path): It reads the contents of a file at the given path and returns them as a string.
concat(["a", ""], ["b", "c"]): It takes two or more lists and combines them into a single list.
urlencode(string): It applies URL encoding to a given string.
jsonencode(string): It encodes a given value to a string using JSON syntax.
policy = jsonencode(
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:ListAllMyBuckets"
],
"Effect": "Allow",
"Resource": "*"
}
]
})
Terraform Console
The terraform console command provides an interactive console for evaluating expressions. If the current state of the deployment is empty or has not yet been created, the console can be used for running built-in functions and expression syntax.
$ terraform console
> max(4, 5, 7, 9)
> timestamp()
> join("_", ["james", "bond"])
> contains(["john", "wick", 2, 4, 6], "wick")
Type Contraints
Type constraints control the type of variable values that can be passed to the Terraform code.
Primitive Type which have single type value.
- number - e.g. replicas = 3
- string - e.g. name = "cluster2"
- bool - e.g. backup = true
Complex Types which have multiple types in a single variable. e.g. list, tuple, map, object.
Complex types can be grouped in Collection type and Structural type.
Collection types allows multiple values of one primitive type to be grouped together against a variable.
Constructors for these Collections include:
- list(<type>)
- map(<type>)
- set(<type>)
variable "training" {
type = list(string) // Variable is list of several strings
default = ["ACG", "GQ"] // Two separate strings in one variable
}
Structural types allow multiple values of different primitive types to be grouped together. Structural type allows more than one type of values assigned within a variable as opposed to a Collection types which allows only a single type of value within a variable.
Constructors for these Collections include:
- object({<attribute_name> = <type>, ... })
- tuple([<type>, ...])
- set(<type>)
variable "instructor" {
type = object({
name = string // Primitive Types
age = number // Several named attributes
})
}
Any Constraint
Any is a placeholder for a primitive type yet to be decided. Terraform allows to leave out the type of the variable while defining it when its an optional field. The Actual type of the variable assigned the any constraint is determined at runtime and assigned a proper primitive type. In the below example were variable is of list type with any constraint. Terraform recognized all the values passed in default value of the variable as numbers, and assign the type of the list as numbers.
variable "data" {
type = list(any)
default = [1, 42, 7]
}
Dynamic Blocks
Dynamic Blocks enable to dynamically construct repeatable nested configuration blocks inside Terraform resources. They can be used within resource blocks, data blocks, provider blocks and provisioners.
Below is the example of Terraform code which creates an AWS Security group which takes several rules, which in-turn take several inputs represented by ingress block as below.
resource "aws_security_group" "my-sg" {
name = 'my-aws-security-group'
vpc_id = aws_vpc.my-vpc.id
ingress {
from_port = 22
to_port = 22
protocol = 'tcp'
cidr_blocks = ["1.2.3.4/32"]
},
ingress {
... # more ingress rules
}
}
The above code with many ingress rule blocks can be streamed line as below. The nested content block defines the body of each generated block using the complex variable provided (var.rules in below example). The ingress variable inside the content block is the iterator argument. The iterator argument can be provided with a custom name, but by default it uses the name of the dynamic block, hence its ingress variable in below example.
resource "aws_security_group" "my-sg" {
name = 'my-aws-security-group'
vpc_id = aws_vpc.my-vpc.id
dynamic "ingress" { // using dynamic block for config block to replicate
for_each = var.rules // for_each loop uses complex variable to iterate over
content {
from_port = ingress.value["port"]
to_port = ingress.value["port"]
protocol = ingress.value["proto"]
cidr_blocks = ingress.value["cidrs"]
}
}
}
The complex variable rules passed in above dynamic block is defined as below.
variable "rules" {
default = [
{
port = 80
proto = "tcp"
cidr_blocks = ["0.0.0.0/0"]
},
{
port = 22
proto = "tcp"
cidr_blocks = ["1.2.3.4/32"]
}
]
}
Dynamic blocks expect a complex variable types to iterate over. They act like a for loops to output a nested block for each element in the (complex) variable passed to them. Dynamic blocks help to make the code cleaner by cutting down on writing repetitive chunks of nested block resources. Overuse of dynamic blocks in the code will make it hard to read and maintain. Dynamic blocks are mostly used to hide detail in order to build a cleaner user interface when writing reusable modules.
Terraform Format
Terraform formats the terraform code for readability. It makes the code consistent and easy to maintain. Terraform format is safe to run at anytime as it just changes the code format. It looks for all the files ending with .tf extension and formats them. It is mostly used before pushing the code to version control and after upgrading Terraform or its modules.
$ terraform fmt
Terraform Taint
The taint command marks/taints the existing terraform resource, forcing it to be destroyed and recreated. It only modifies the state file which tracks the resources which are created. The state file is marked with the resources to be tainted which causes the recreation workflow. After tainting the resource which causes it to be destroyed, the next terraform apply causes it to be recreated. Tainting a resource may cause other dependent resources to be modified as well, e.g. tainting a virtual machine with ephemeral public IP address will cause the public IP address to change when the resource is recreated.
Terraform taint command takes the resource address within the Terraform code.
$ terraform taint <resource-address>
Taint command is generally used to trigger the execution of provisioners (by resource create/destroy), replace bad resources forcefully and replicate the side effects of recreation process.
The untaint command is used to remove the taint from a resource.
$ terraform untaint <resource-address>
Terraform Import
Terraform import command takes the existing resource which is not managed by Terraform and maps to a resource within terraform code using an ID. The ID is dependent on the underlying vendor infrastructure from which the resource is imported, for e.g. to import an AWS EC2 instance we need to provide its instance ID. Importing the same resource to multiple Terraform resources can cause unknown behavior and is not recommended. Terraforms ensures that there is one-to-one mapping between its resources and real world resources, but cannot prevent same resource being added using Terraform import.
The import command syntax is as below which takes the resource address i.e. the terraform resource name to be mapped with real world resource and ID of the real world resource.
$ terraform import <resource-address> ID
Terraform import is helpful in working with the existing resources, and enables them to be managed using Terraform. The user can import resources even though has no access to create new resources. If there are a lot of existing resources to be imported into Terraform, writing Terraform code for all of them would be time consuming process. In such case
Terraforming tool allows to import both code and state from an AWS account automatically.
Terraformer is a CLI tool that generates tf/json and tfstate files based on existing infrastructure, reverse converting real world infrastructure into Terraform.
Terraform Show
The
terraform show command provides human-readable output from a state or plan file
$ terraform show <path-to-state-or-plan-file>
The -json command line flag prints the state or plan file in JSON format.
$ terraform show -json <state-plan-file>
$ terraform show -json tfplan.binary > tfplan.json
Miscellaneous Terraform Commands
In order to provide Terraform command
completion using tab for either bash or zsh shell, we run the below command.
$ terraform -install-autocomplete
The terraform validate command validates the configuration files in current directory without accessing any remote services such as remote state, provider APIs etc. It checks whether the configuration code syntax is valid and consistent, and ensures the correctness of attribute names and value types. It support -json flag to output validation results in JSON format.
$ terraform validate
The get command downloads and updates the modules mentioned in the root module. The -update option checks for updates and updates the already downloaded modules.
$ terraform get -update=true
The terraform graph command is used to generate a graph in DOT format of either a configuration or execution plan. It shows the relationship and dependencies between Terraform resource in the configuration code. The dot utility to generate PNG images can be downloaded from
Graphviz.
$ sudo apt install graphviz
$ terraform graph | dot -Tsvg > graph.svg
Provisioners
Provisioners allow users to execute custom scripts, commands and actions. We can be either run such scripts locally or remotely on resources spun up through the Terraform deployment. A provisioner is attached to terraform resource which allows custom connection parameters that can be passed to connect to remote resources using ssh or WinRM to carry out commands against that resource. Within Terraform code, each individual resource can have its own provisioner defining the connection method and actions/commands or scripts to execute.
There are 2 types of provisioners which cover two types of events in terraform resources lifecycle.
The Create-time provisioner and Destroy-time provisioner, can be set to run when a resource is being created or destroyed respectively. HashiCorp recommends using Provisioners as a last resort and to use inherent mechanisms provided by cloud vendors within the infrastructure deployment to carry out custom tasks where possible. Provisioners are used only when underlying vendor such as AWS does not provide a built in mechanism for bootstrapping via custom commands or scripts. Terraform cannot track changes to provisioners as they can take any independent action via script or command, hence they are not tracked by Terraform state files. Hence the provisioners changes are not provided as part of the output of terraform plan/apply command.
Provisioners are recommended for use when we want to invoke actions that are not covered by Terraforms declarative model or through inherent options for the resources in available providers. Provisioners expect any custom script or commands to be executed with the return code of zero. If the command within a provisioner returns non-zero return code, then it is considered failed and underlying resource is tainted (marking the resource against which the provisioner is to be ran, to be created during next run).
Below is the example of the provisioner. By default the provisioner is a create provisioner, i.e. the provisioner by default executes once the resource is created within the same directory.
resource "null_resource" "dummy_resource" {
provisioner "local-exec" {
command = "echo '0' > status.txt"
}
provisioner "local-exec" {
when = destroy
command = "echo '1' > status.txt"
}
}
We can use multiple provisioners against the same resource and they are executed in the order in the code.
Accessing resource using variable convention inside the provisioner can cause cyclical dependencies, causing the provisioner to run a command against the resource which has not been created, because provisioner is independent of the terraform plans. The self object can access any attribute available to the resource, which is attached to the provisioner.
resource "aws_instance" "ec2-virtual-instance" {
ami = ami-12345
instance_type = t2.micro
key_name = aws_key_pair.master-key.key_name
associate_publice_ip_address = true
vpc_security_group_ids = [aws_security_group.jenkins-sg.id]
subnet_id = aws_subnet.subnet.id
provisioner "local-exec" {
command = "aws ec2 wait instance-status-ok --region us-west-1 --instance-ids ${self.ids}"
}
}
Workspace
Terraform Workspaces aka CLI are alternate state files within the same working directory. By keeping alternate state files for the same code or configuration, distinct environments can be spun up. Terraform starts with a single default workspace which cannot be deleted. Each workspace tracks a separate independent copy of the state file against terraform code in that directory. Below are the terraform workspace subcommands.
Create a new workspace
$ terraform workspace new <workspace-name>
Lists all the available terraform workspaces and highlights the current workspace using an asterisk (*).
$ terraform workspace list
The Terraform workspace show command displays the current workspace.
$ terraform workspace show
Selects and switches to an existing terraform workspace
$ terraform workspace select <workspace-name>
Terraform workspace is used to test changes using a parallel, distinct copy of an infrastructure. Since each workspace tracks an independent copy of the state file, Terraform can deploy a new environment for each workspace using the common terraform code. It can be modeled against branches, by committing terraform state files in version control such as Git.
Workspaces are meant for sharing resources and enabling collaboration between teams. Each team can test the same common code using different workspaces. Terraform code can access the Workspace name using the ${terraform.workspace} variable. The workspace name can be used within the resources to associate them to the workspace or to perform certain unique actions on the resources based on the workspace name.
In the below example we spin up 5 EC2 instances if current workspace is default workspace, or else only spin up a single EC2 instance in AWS cloud, using the ${terraform.workspace} variable.
resource "aws_instance" "example" {
count = terraform.workspace == "default" ? 5 : 1
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "${terraform.workspace}-instance"
}
}
Another example below is to switch the region based on the current workspace in AWS provider config.
provider "aws" {
region = terraform.workspace == "default" ? "us-east-2" : "us-west-1"
}
The default workspace state file is the terraform.tfstate file in the root directory. Terraform State files for non-default workspaces are stored into the terraform.tfstate.d directory.
Managing Terraform Secrets
Secrets such as passwords, API keys, and other sensitive data should not be stored directly in Terraform code in plain text. Terraform state file which contains all the secrets should be stored with encryption. There are various techniques of managing secrets in Terraform as below.
We can pass the secrets using environment variables to the Terraform code. Secrets can be passed as environment variables (prefixed with TF_VAR) to set terraform variable values, referenced in resource for credentials. Passwords and secure data passed to environment variables can be stored and managed using a password manager such as
1Password,
LastPass or
pass. Passwords can be stored using tools like
pass which is a unix CLI tool which takes input and output via stdin and stdout, storing password in PGP encrypted files.
$ pass insert db_username
Enter password for db_username: admin
$ pass db_username
admin
Another technique relies on encrypting the secrets, storing the cipher text in a file, and checking that file into version control. The Cloud Key Service like AWS KMS, GCP KMS, Azure Key Vault is used to store the key and encrypt the credentials file.
$ aws kms create-key --description "KMS Demo Application"
We add the secret credentials in credentials.yml file and use below AWS KMS command to encrypt using KMS key.
$ aws kms encrypt \
--key-id <AWS_KMS_key> \
--region <AWS_Region> \
--plaintext fileb://credentials.yml \
--output text \
--query CiphertextBlob \
> credentials.yml.encrypted
Then aws_kms_secrets data source for AWS (google_kms_secret for GCP KMS or azurerm_key_vault_secret for Azure Key Vault) is used to decrypt the secret credentials by reading credentials.yml.encrypted file.
data "aws_kms_secrets" "creds" {
secret {
name = "db"
payload = file("${path.module}/credentials.yml.encrypted")
}
}
locals {
db_creds = yamldecode(data.aws_kms_secrets.creds.plaintext["db"])
}
resource "aws_db_instance" "mysql_test_instance" {
engine = "mysql"
engine_version = "5.7"
instance_class = "db.t2.micro"
name = "mysql_test_instance"
username = local.db_creds.username
password = local.db_creds.password
}
Sops is an open source tool designed to make it easier to edit and work with files that are encrypted via AWS KMS, GCP KMS, Azure Key Vault, or PGP. sops can automatically decrypt a file when you open it in your text editor, so you can edit the file in plain text, and when you go to save those files, it automatically encrypts the contents again. This removes the need to run long aws kms commands to encrypt or decrypt data or worry about accidentally checking plain text secrets into version control. Terragrunt has native built in support for sops. The terragrunt.hcl can use the sops_decrypt_file function built into Terragrunt to decrypt that file and yamldecode to parse it as YAML.
locals {
db_creds = yamldecode(sops_decrypt_file(("db-creds.yml")))
}
We can also directly store the terraform secrets in a dedicated cloud secret store, which is a database, designed specifically for securely storing sensitive data and tightly controlling access to it. The Cloud Secret Stores such as HashiCorp Vault, AWS Secrets Manager, AWS Param Store, GCP Secret Manager etc can be used to store secrets. The AWS Secrets Manager uses aws_secretsmanager_secret_version, HashiCorp Vault uses vault_generic_secret, AWS SSM Param Store uses aws_ssm_parameter and GCP Secret Store uses google_secret_manager_secret_version data source to read the secrets stored in respective cloud secret store.
data "aws_secretsmanager_secret_version" "creds" {
secret_id = "db-creds"
}
locals {
db_creds = jsondecode(
data.aws_secretsmanager_secret_version.creds.secret_string
)
}
Debugging Terraform
The TF_LOG is an environment variable which enables verbose logging in Terraform. By default, it sends logs to the standard error output (stderr) displayed on the console. The Terraform logs have 5 levels of verbosity, with following levels: TRACE, DEBUG, INFO, WARN AND ERROR. TRACE is the most verbose level of logging and both terraform internal logs along with backend API calls made to cloud providers. We can redirect the output logs to persist into a file by setting the TF_LOG_PATH environment variable to a file name. By default TF_LOG_PATH is disabled, but can be enabled by setting a value to the environment variable as below.
$ export TF_LOG=TRACE
$ export TF_LOG_PATH=./terraform.log
HashiCorp Sentinel
HashiCorp Sentinel is a feature provided in Terraform Enterprise version. HashiCorp Sentinel enforces policies (restrictions) on the Terraform code. Sentinel has its own policy language called Sentinel language. It prevents dangerous and malicious code is stopped even before it gets executed or applied using the terraform apply command. The sentinel integration runs in enterprise terraform after terraform plan and before terraform apply command. The sentinel's policies have access to the data in the created plan and the state of resources & configuration at the time of the plan. Sentinel codifies the security policies in terraform code which can also be version controlled. It provides guardrails for automation and sandboxing. Below is the example of
sentinel policy code which only allows to create EC2 instances with instance types t2.small, t2.medium or t2.large.
import "tfplan-functions" as plan
allowed_types = ["t2.small", "t2.medium", "t2.large"]
allEC2Instances = plan.find_resources("aws_instance")
violatingEC2Instances = plan.filter_attribute_not_in_list(allEC2Instances,
"instance_type", allowed_types, true)
violations = length(violatingEC2Instances["messages"])
main = rule {
violations is 0
}
HashiCorp Vault
HashiCorp Vault is a secrets management software which stores sensitive data securely and provides short lived temporary credentials to users. Vault handles the rotating these temporarily credentials as per an expiration schedule which is configurable. It generates cryptographic keys which are used to encrypt sensitive data at rest or in transit, and provides fine-grained access to secrets using ACLs.
The Vault admin stores the ACLs and long lived credentials in Vault and configures permissions for temporary generated credentials using Vault's integration with AWS or GCP's IAM service or Azure RBAC. The Terraform Vault Provider allows to integrate Vault into Terraform code, and allows to access temporarily short-lived credentials with appropriate IAM permissions. Terraforms uses these credentials for deployment with the terraform apply command. Vault allows fine grained ACLs for access to temporary credentials.
Terraform Cloud
Terraform Cloud is HashiCorp's
cloud solution which allows to execute Terraform code on cloud hosted system. It simplifies environment management, code execution, state file management, as well as permissions management.
Terraform Cloud allows to create remote workspace, maintaining a separate directory for each workspace host in the cloud. Terraform Cloud manages storage & security of Terraform State files, variables and secrets within the cloud workspace. It stores older versions of state files by default. Terraform Cloud Workspace maintains records of all execution activity within the workspace. All Terraform commands can be executed using Terraform CLI, Terraform Workspace APIs, Github Actions or Terraform Cloud GUI, within the Terraform Cloud managed VMs. Terraform Cloud integrates with various version control systems e.g. Github, Bitbucket to fetch latest terraform code. Terraform Cloud also provides cost estimation for the terraform deployment.
Terragrunt
Terragrunt is a thin wrapper, command line interface tool to make Terraform better or build a better infrastructure as code pipeline. It provides extra tools for keeping the configurations DRY (Don't Repeat Yourself), working with multiple Terraform modules, and managing remote state. Terragrunt helps with code structuring were we can write the Terraform code once and apply the same code with different variables and different remote state locations for each environment. it also provides before and after hooks, which make it possible to define custom actions that will be called either before or after execution of the terraform command.
Terragrunt Configuration
Terragrunt configuration is defined in a terragrunt.hcl file. This uses the same HCL syntax as Terraform itself. Terragrunt also supports JSON-serialized HCL defined in a terragrunt.hcl.json. Terragrunt by default checks for terragrunt.hcl or terragrunt.hcl.json file in the current working directory. We can also pass command line argument --terragrunt-config or set TERRAGRUNT_CONFIG environment variable specifying the config path, overriding the default behavior.
# vim: set syntax=terraform:
skip = local.toplevel.inputs.stage == "rd"
include {
path = find_in_parent_folders()
}
dependencies {
paths = [
"../base",
"../pub"
]
}
locals {
topLevel = read_terragrunt_config(find_in_parent_folders())
stack = get_env("MY_STACK")
local.region = "us-west-1"
}
remote_state {
backend = "s3"
config = {
bucket = "${local.toplevel.inputs.account_name}-terraform-state"
key = "${path_relative_to_include()}/terraform.tfstate"
region = local.region
encrypt = local.toplevel.remote_state.config.encrypt
dynamodb_table = local.toplevel.remote_state.config.dynamodb_table
}
}
inputs = {
cft_generator_image = get_env("MY_IMAGE_cft-generator", "IMAGE_NA")
}
skip = !contains(["dev", "cert"], local.stack)
Terragrunt Features
In software development, we often need to setup up multiple environments (quality, stage, production) for different phases of software development. The terraform contents for each environment would be more or less identical, except perhaps for a few settings. Although terraform modules provides a solution to reduce duplicate code, it requires to set up input variables, output variables, providers, and remote state, adding more maintenance overhead.
Terragrunt provides the ability to download remote Terraform configurations. We define Terraform infrastructure code once with any configuration which is different across environments being exposed as terraform input variable. We then define terragrunt.hcl file with a terraform { ... } block that specifies from where to download the Terraform code, as well as the environment-specific values for the input variables in that Terraform code. Below is an example of env-name/application/terragrunt.hcl file. The below source parameter specifies the location of module to deploy and the inputs specifies the input values for the current environment.
terraform {
source = "git::git@github.com:foo/modules.git//app?ref=v0.0.3"
}
inputs = {
instance_count = 3
instance_type = "t2.micro"
}
Terragrunt downloads the configuration code specified via the source parameter, along with modules, providers into the .terragrunt-cache directory (in current directory) by default. Once downloaded it reuses the config/module files for the subsequent commands. It then copies all files in current directory to temp directory and executes the Terraform command in the temp directory. Terragrunt passes any variables defined in the inputs block as environment variables (prefixed with TF_VAR_) to the Terraform code. Terragrunt downloads the code in tmp directory only for the first time, and skips the download step subsequently unless the source URL is changed. The --terragrunt-source command-line option or the TERRAGRUNT_SOURCE environment variable is used to override the source parameter in .hcl files. If the source parameter refers local file path, then Terragrunt copies the local files in tmp directory for every execution.
Although Terraform supports remote state storage for various backend cloud storage, it does not support expressions, variables, or functions. Hence the remote state config would in most cases have to be duplicated across multiple terraform modules. With Terragrunt, although the terraform backend is specified in main.tf for each module, it is left blank and the entire remote state configuration is defined in the remote_state block within the single terragrunt.hcl at the root level. Each child terragrunt.hcl file automatically includes all the settings from the root terragrunt.hcl file using include block. The include block tells Terragrunt to use the exact same Terragrunt configuration from the terragrunt.hcl file specified via the path parameter (with find_in_parent_folders() or path_relative_to_include() path value).
terraform {
# The configuration for this backend will be filled in by Terragrunt
backend "s3" {}
}
Terragrunt enables to configure passing specific CLI arguments for specific commands using an extra_arguments block in the terragrunt.hcl file. There could be more than one extra_arguments block in the hcl file. Terragrunt's run-all command enables to deploy multiple Terraform modules using a single command. Terragrunt allows to add before and after hooks in order to execute pre-defined custom actions before or after execution of the terraform command.
Terragrunt auto initializes by default and automatically calls the terraform init during other terragrunt commands (e.g. terragrunt plan) if it detects that the terraform init is never called, sources are not downloaded or modules/remote state is recently updated. It also automatically re-runs the terraform command again when Terraform fails with transient errors. Terragrunt provides a way to configure logging level through the --terragrunt-log-level command flag. It also provides --terragrunt-debug, that can be used to generate terragrunt-debug.tfvars.json.
Terragrunt allows to assume an AWS IAM role using
--terragrunt-iam-role command line argument or
TERRAGRUNT_IAM_ROLE environment variable. It can also automatically load credentials using the
Standard AWS approach.
Terragrunt Configuration Blocks
Terragrunt has below config blocks which are used to configure and interact with Terraform. Terragrunt parses the config blocks in below order of precedence:
- include block
- locals block
- terraform block (of all configurations when -all flavored commands are used)
- dependencies block
- dependency block (for -all flavored commands, dependency block is executed before terraform block)
- everything else
- config referenced by include
Blocks that are parsed earlier in the process will be made available for use in the parsing of later blocks. But we cannot use blocks that are parsed later, in the blocks earlier in the process.
terraform block
The
terraform block is used to configure how Terragrunt interacts with Terraform. It specifies where to find the Terraform configuration files or if there are any to hooks to run before or after calling Terraform. Below are the arguments supported by terraform block.
source (attribute): It specifies the location to the Terraform configuration files. It supports the exact same syntax as the
module source parameter, allowing local file paths, Git URLs, and Git URLs with ref parameters.
extra_arguments (nested block): It allows to pass extra arguments to the terraform CLI. We can also pass sub commands, map of environment variables and list of file paths to terraform vars files (.tfvars).
terraform {
extra_arguments "retry_lock" {
commands = [
"init",
"apply"
]
arguments = [
"-lock-timeout=20m"
]
env_vars = {
TF_VAR_var_from_environment = "value"
}
}
}
before_hook (nested block): It specifies command hooks that run before terraform is called. Hooks run from the directory with the terraform module or where terragrunt.hcl lives. It takes list of terraform sub commands for which the hook should run before, the list of commands (& args) that should be run as the hook, the working directory of the hook and flag indicating to run hook even if a previous hook hit an error.
after_hook (nested block): It specifies command hooks that run after terraform is called. Hooks run from the directory where terragrunt.hcl lives. It supports same arguments as before_hook.
terraform {
source = "git::git@github.com:acme/infrastructure-modules.git//networking/vpc?ref=v0.0.1"
extra_arguments "retry_lock" {
commands = get_terraform_commands_that_need_locking()
arguments = ["-lock-timeout=20m"]
}
before_hook "before_hook_2" {
commands = ["apply"]
execute = ["echo", "Bar"]
run_on_error = true
}
}
remote_state block
The
remote_state block is used to configure remote state configuration for Terraform code using Terragrunt. It supports the following arguments:
disable_init (attribute): It allows to skip automatic initialization of the backend by Terragrunt. The s3 and gcs backends have support in Terragrunt for automatic creation if the storage does not exist. By default it is set to false.
disable_dependency_optimization (attribute): It disables optimized dependency fetching for terragrunt modules using this remote_state block.
generate (attribute): Configure Terragrunt to automatically generate a .tf file that configures the remote state backend. This is a map that expects two properties
config (attribute): An arbitrary map that is used to fill in the backend configuration in Terraform. All the properties will automatically be included in the Terraform backend block (with a few exceptions: see below). Terragrunt does special processing of the config attribute for the s3 and gcs remote state backends, and supports additional keys that are used to configure the automatic initialization feature of Terragrunt.
remote_state {
backend = "s3"
config = {
bucket = "testbucket"
key = "path/to/test/key"
region = "us-west-1"
}
}
include block
The
include block is used to specify inheritance of Terragrunt configuration files. The included config (called as parent) will be merged with the current configuration (called the child) before processing. It support below arguments:
path (attribute): It specifies the path of the Terragrunt configuration file (parent config) that should be merged with the current (child) configuration.
expose (attribute, optional): It specifies whether or not the included config should be parsed and exposed as a variable. The data of the included config can be referenced using the variable under include.
merge_strategy (attribute, optional): It determines how the included config would be merged. Its values include no_merge (do not merge the included config), shallow (do a shallow merge - default), deep (do a deep merge of the included config).
include {
path = find_in_parent_folders()
expose = true
}
inputs = {
remote_state_config = include.remote_state
}
locals block
The
locals block is used to define aliases for Terragrunt expressions that can be referenced within the configuration. The locals block does not have a defined set of arguments that are supported. Instead, all the arguments passed into locals are available under the reference local.ARG_NAME throughout the Terragrunt configuration.
locals {
aws_region = "us-east-1"
}
inputs = {
region = local.aws_region
name = "${local.aws_region}-bucket"
}
dependency block
The
dependency block is used to configure module dependencies. Each dependency block exports the outputs of the target module as block attributes which can be referenced throughout the configuration. We can define more than one dependency block, with each block identified using a label. The dependency blocks are fetched in parallel at each source level, but each recursive dependency will be parsed serially. The dependency block supports the below arguments:
name (label): It is used by each dependency block to differentiate from other dependency blocks in the terragrunt configuration. It is used to reference the specific dependency by name.
config_path (attribute): It specifies the path to a Terragrunt module (directory containing terragrunt.hcl) to be included as a dependency in the current configuration.
skip_outputs (attribute): It skips calling terragrunt output when processing this dependency, when set true.
mock_outputs (attribute): A map of arbitrary key value pairs to be used as the outputs attribute when no outputs are available from the target module, or when skip_outputs is set to true.
mock_outputs_allowed_terraform_commands (attribute): A list of Terraform commands for which mock_outputs are allowed. If a command is used where mock_outputs is not allowed, and no outputs are available in the target module, Terragrunt will throw an error when processing this dependency.
mock_outputs_merge_with_state (attribute): It merges the mock_outputs with the state outputs when enabled.
dependency "vpc" {
config_path = "../vpc"
mock_outputs_allowed_terraform_commands = ["validate"]
mock_outputs = {
vpc_id = "fake-vpc-id"
}
}
dependency "rds" {
config_path = "../rds"
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
db_url = dependency.rds.outputs.db_url
}
dependencies block
The
dependencies block enumerates all the Terragrunt modules that need to be applied in order for current module to be able to apply. It supports the paths attribute as below:
paths (attribute): A list of paths to modules that should be marked as a dependency.
dependencies {
paths = ["../vpc", "../rds"]
}
generate block
The
generate block is used to arbitrarily generate a file in the terragrunt working directory (where terraform is called). This enables to generate common terraform configurations that are shared across multiple terraform modules. The generate block supports the below arguments:
name (label): The name to identify the generate block as multiple generate blocks can be defined in a terragrunt config.
path (attribute): The path where the generated file should be written. If a relative path, it’ll be relative to the Terragrunt working dir.
if_exists (attribute): It specifies whether to always overwrite the existing file (overwrite), or overwrite only on error (overwrite_terragrunt) or skip file write (skip) or exit with error (error), when a file already exists in the specified path attribute.
comment_prefix (attribute): A prefix (default #) which can be used to indicate comments in the generated file.
disable_signature (attribute): It disables including a signature in the generated file, when set as true.
contents (attribute): The contents of the generated file.
generate "provider" {
path = "provider.tf"
if_exists = "overwrite"
contents = <<EOF
provider "aws" {
region = "us-east-1"
version = "= 2.3.1"
allowed_account_ids = ["1234567890"]
}
EOF
}
Terragrunt Configuration Attributes
inputs: The
input attribute is a map that is used to specify the input variables and their values to pass in to Terraform. Each entry is passed to terraform using the form TF_VAR_variablename, with the value in json encoded format.
download_dir: The
download_dir string option is used to override the default download directory.
prevent_destroy: The
prevent_destroy boolean flag prevents destroy or destroy-all command to actually destroy resources of the selected Terraform module, thus protecting the module.
skip: The
skip boolean flag skips the selected terragrunt module, protecting it from any changes or ignoring them if they do not define any infrastructure by themselves.
iam_role: The
iam_role attribute can be used to specify an IAM role that Terragrunt should assume prior to invoking Terraform.
terraform_binary: The
terraform_binary string option overrides the default terraform binary path.
terraform_version_constraint: The
terraform_version_constraint string overrides the default minimum supported version of terraform. Terragrunt supports the latest version of terraform by default.
retryable_errors: The
retryable_errors list overrides the default list of retryable errors with this custom list.
Terragrunt Built-in functions
All Terraform built-in functions are supported in Terragrunt config files. Terragrunt also has the following built-in functions which can be used in terragrunt.hcl.
find_in_parent_folders(): It searches up the directory tree from the current terragrunt.hcl file and returns the absolute path to the first terragrunt.hcl in a parent folder or exit with an error if no such file is found. It also takes optional name parameter to search with different filename and fallback value to return if filename not found.
path_relative_to_include(): It returns the relative path between the current terragrunt.hcl file and the path specified in its include block.
path_relative_from_include(): It returns the relative path between the path specified in its include block and the current terragrunt.hcl file.
get_env(NAME, DEFAULT): It returns the value of variable named NAME. If variable not set then it returns the DEFAULT value if set, or else it throws an exception.
get_platform(): It returns the current Operating System.
get_terragrunt_dir(): It returns the directory where the Terragrunt configuration file (by default terragrunt.hcl) lives.
get_parent_terragrunt_dir(): It returns the absolute directory where the Terragrunt parent configuration file (by default terragrunt.hcl) lives.
get_terraform_commands_that_need_vars(): It returns the list of terraform commands that accept -var and -var-file parameters.
get_terraform_commands_that_need_input(): Returns the list of terraform commands that accept the -input=(true or false) parameter. Similar functions are available to return terraform commands accepting -locl-timeout and -parallelism parameter s.
get_terraform_command(): It returns the current terraform command in execution.
get_terraform_cli_args(): It returns cli args for the current terraform command in execution.
get_aws_account_id(): It returns the AWS account id associated with the current set of credentials.
get_aws_caller_identity_arn(): It returns the ARN of the AWS identity associated with the current set of credentials.
run_cmd(command, arg1, ..): It runs the specified shell command and returns the stdout as the result of the interpolation. The --terragrunt-quiet argument prevents terragrunt to display the output into the terminal to redact sensitive values. The invocations of run_cmd are cached based on directory and executed command.
read_terragrunt_config(config_path, [default_val]): It parses the terragrunt config in the specified path and serializes the result into a map which can be used to reference the values of the parsed config. It exposes all the attributes and blocks in the terragrunt configuration, along with outputs from dependency blocks. The optional default value is returned if file does not exist.
sops_decrypt_file(): It decrypts a yaml or json file encrypted with
sops
get_terragrunt_source_cli_flag(): It returns the value passed in via the CLI --terragrunt-source or an environment variable TERRAGRUNT_SOURCE. It returns an empty string when neither of those values are not provided.
Terragrunt Commands
Since Terragrunt is a thin wrapper for Terraform, with few exceptions of special commands, Terragrunt forwards all other commands to Terraform. Hence when we run terragrunt apply, Terragrunt executes terraform apply.
$ terragrunt <terraform-command>
$ terragrunt init
$ terragrunt plan
$ terragrunt apply
$ terragrunt destroy
The Terragrunt run-all command runs the provided terraform command against a stack, which is a tree of terragrunt modules. The command will recursively find terragrunt modules in the current directory tree and run the terraform command in each module, in the defined dependency ordering.
$ terragrunt run-all <terraform-command>
$ terragrunt run-all apply
The below command outputs the current terragrunt state (in limited form) in JSON format.
$ terragrunt terragrunt-info
The validate-inputs command outputs the information about the input variables configured with the given terragrunt configuration. It specifically prints out unused inputs not defined in corresponding Terraform module and undefined required terraform inputs variables which are not being passed. Byt default it runs in related mode and can run in strict mode using --terragrunt-strict-validate flag.
$ terragrunt validate-inputs
The below command prints the terragrunt dependency graph in DOT format. It recursively searches the current directory for Terragrunt modules and builds the dependency graph based on dependency and dependencies blocks.
$ terragrunt graph-dependencies
The HCL format command recursively searches for hcl files under a given directory tree and formats them. The --terragrunt-check flag allows to only verify the file formats without rewriting them.
$ terragrunt hclfmt
$ terragrunt hclfmt --terragrunt-check
tfsec Scanner
tfsec is a static analysis security scanner for the Terraform code. It uses deep integration with the official HCL parser to ensure security issues can be detected before the infrastructure changes take effect.
The tfsec config file is a file in the .tfsec folder in the root, named as config.json or config.yml. It is automatically loaded if it exists. The config file can also be set with the --config-file option:
$ tfsec --config-file tfsec.yml
The tfsec config file contains the severity overrides and check exclusions. The "
severity_overrides" section increases or decreases the severity for any check identifier. The "
exclude" section allows to specify the list of check identifiers to be excluded from the scan. The check identifiers can be found left menu, under
provider checks.
The below tsec command scans the specified directory or current directory if not directory is specified.
$ tfsec <directory-path>
TerraTest
Terraform supports
unit testing,
acceptance testing and
end to end testing.
Terratest is a unit testing framework which uses Go’s unit testing framework and
Go libraries. It provides a variety of helper functions and patterns for common infrastructure testing tasks.
Tests are written using Go with Terraform file passed as argument and is invoked using "
go test" command which initializes and applies the infrastructure. Once the tests are complete it destroys the infrastructure.
Terratest provides a whole range of
Go modules to help with the testing.










